
课程链接:【Siraj】 深度学习引论#2 如何做一个神经网络
1 Intro to Deep Learning
本周总结:
- 神经网络是一种在数据中识别模式的算法
- 反向传播是一种在更新权重的训练过程中采用的一种技术,这个过程使用的是梯度下降法。
- 深度学习 = 多层神经网络 + 大数据 + 大量的计算
实例
课程实例中构建了一个最简单的单层神经网络,并且只含一个神经元。和吴恩达的第二周机器学习课程神经网络基础基本是相同的,有时间回头在做详细的对比。其中也应用神经网络做了一个简单的预测,样本集应该是随便给的把,看起来没什么规律,主要是揭示神经网络构建和应用的基本流程。
from numpy import exp, array, random, dot
class NeuralNetwork():
def __init__(self):
# 设置随机数种子,使每次运行生成的随机数相同
# 便于调试
random.seed(1)
# 我们对单个神经元进行建模,其中有3个输入连接和1个输出连接
# 我们把随机的权值分配给一个3x1矩阵,值在-1到1之间,均值为0。
self.synaptic_weights = 2 * random.random((3, 1)) - 1
# Sigmoid函数, 图像为S型曲线.
# 我们把输入的加权和通过这个函数标准化在0和1之间。
def __sigmoid(self, x):
return 1 / (1 + exp(-x))
# Sigmoid函数的导函数.
# 即使Sigmoid函数的梯度
# 它同样可以理解为当前的权重的可信度大小
# 梯度决定了我们对调整权重的大小,并且指明了调整的方向
def __sigmoid_derivative(self, x):
return x * (1 - x)
# 我们通过不断的试验和试错的过程来训练神经网络
# 每一次都对权重进行调整
def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations):
for iteration in range(number_of_training_iterations):
# 把训练集传入神经网络.
output = self.think(training_set_inputs)
# 计算损失值(期望输出与实际输出之间的差。
error = training_set_outputs - output
# 损失值乘上sigmid曲线的梯度,结果点乘输入矩阵的转置
# 这意味着越不可信的权重值,我们会做更多的调整
# 如果为零的话,则误区调制
adjustment = dot(training_set_inputs.T, error * self.__sigmoid_derivative(output))
# 调制权值
self.synaptic_weights += adjustment
# 神经网络的“思考”过程
def think(self, inputs):
# 把输入数据传入神经网络
return self.__sigmoid(dot(inputs, self.synaptic_weights))
if __name__ == "__main__":
# 初始化一个单神经元的神经网络
neural_network = NeuralNetwork()
# 输出随机初始的参数作为参照
print("Random starting synaptic weights: ")
print(neural_network.synaptic_weights)
# 训练集共有四个样本,每个样本包括三个输入一个输入
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
# 用训练集对神经网络进行训练
# 迭代10000次,每次迭代对权重进行微调.
neural_network.train(training_set_inputs, training_set_outputs, 10000)
# 输出训练后的参数值,作为对照。
print("New synaptic weights after training: ")
print(neural_network.synaptic_weights)
# 用新样本测试神经网络.
print("Considering new situation [1, 0, 0] -> ?: ")
print(neural_network.think(array([1, 0, 0])))
Challenge
The challenge for this video is to create a 3 layer feedforward neural network using only numpy as your dependency. By doing this, you’ll understand exactly how backpropagation works and develop an intuitive understanding of neural networks, which will be useful for more the more complex nets we build in the future. Backpropagation usually involves recursively taking derivatives, but in our 1 layer demo there was no recursion so was a trivial case of backpropagation. In this challenge, there will be. Use a small binary dataset, you can define one programmatically like in this example.Bonus – use a larger, more interesting dataset
这一周的作业是自己构建一个三层的神经网络(两隐含层),思路基本一致,将初始话权值,计算损失值,调制权值的过程重复的多做几次就好了(也可以用循环)。下面的程序就是在可以在实例(单神经元神经网络)的基础上做了修改,样本集没变。神经网络结构如下图: 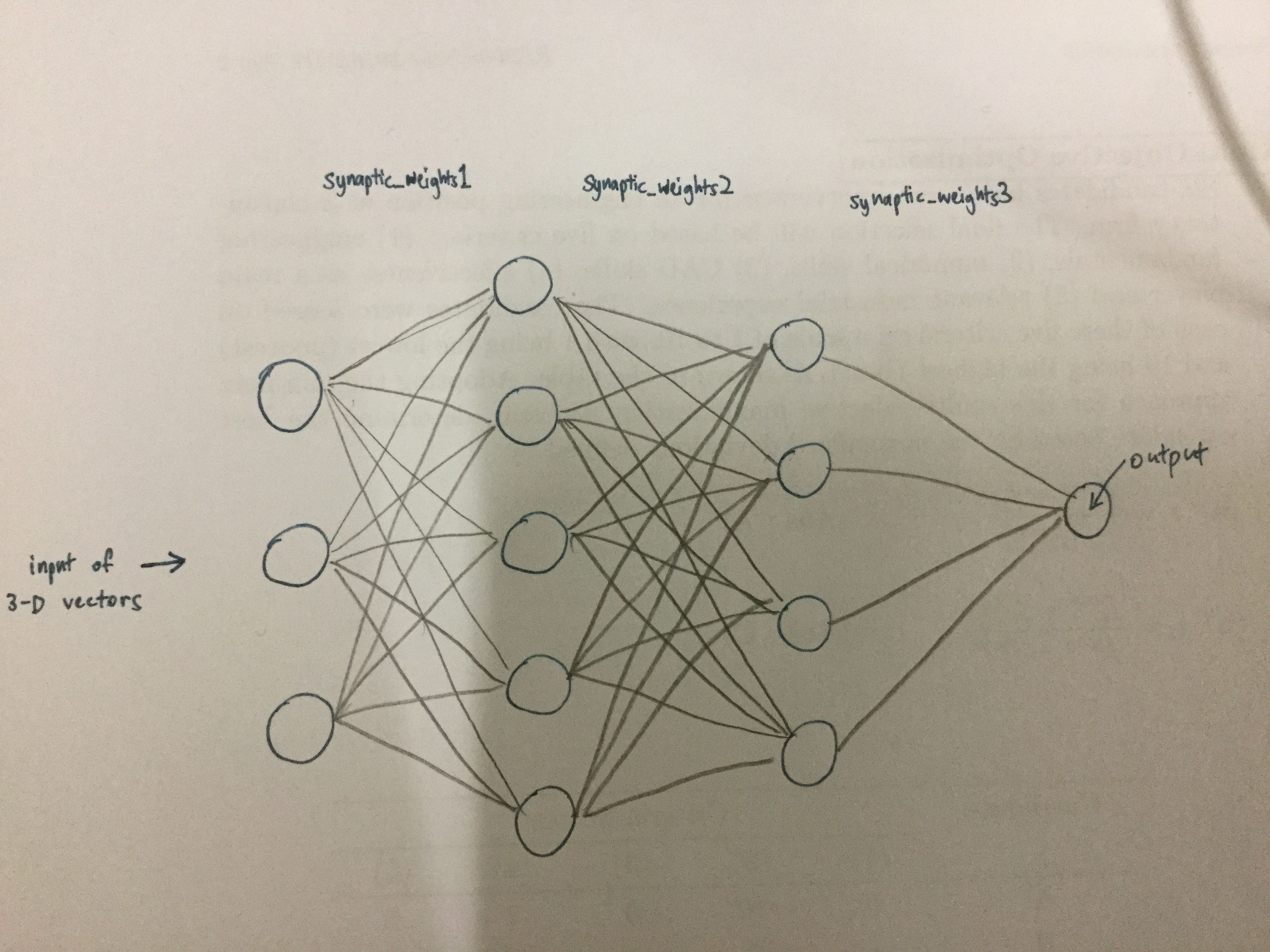
# Mine
from numpy import exp, array, random, dot
class NeuralNetwork():
def __init__(self):
random.seed(1)
# 输入层三个神经元作为第一层
# 第二层定义为5个神经元
# 第三层定义为4个神经元
layer2 = 5
layer3 = 4
# 随机初始化各层权重
self.synaptic_weights1 = 2 * random.random((3, layer2)) -1
self.synaptic_weights2 = 2 * random.random((layer2, layer3)) -1
self.synaptic_weights3 = 2 * random.random((layer3, 1)) -1
def __sigmoid(self, x):
return 1 / (1 + exp(-x))
def __sigmoid_derivative(self, x):
return x * (1 - x)
def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations):
for iteration in range(number_of_training_iterations):
# 正向传播过程,即神经网络“思考”的过程
activation_values2 = self.__sigmoid(dot(training_set_inputs, self.synaptic_weights1))
activation_values3 = self.__sigmoid(dot(activation_values2, self.synaptic_weights2))
output = self.__sigmoid(dot(activation_values3, self.synaptic_weights3))
# 计算各层损失值
delta4 = (training_set_outputs - output)*self.__sigmoid_derivative(output)
delta3 = dot(self.synaptic_weights3, delta4.T)*(self.__sigmoid_derivative(activation_values3).T)
delta2 = dot(self.synaptic_weights2, delta3)*(self.__sigmoid_derivative(activation_values2).T)
# 计算需要调制的值
adjustment3 = dot(activation_values3.T, delta4)
adjustment2 = dot(activation_values2.T, delta3.T)
adjustment1 = dot(training_set_inputs.T, delta2.T)
# 调制权值
self.synaptic_weights1 += adjustment1
self.synaptic_weights2 += adjustment2
self.synaptic_weights3 += adjustment3
def think(self, inputs):
activation_values2 = self.__sigmoid(dot(inputs, self.synaptic_weights1))
activation_values3 = self.__sigmoid(dot(activation_values2, self.synaptic_weights2))
output = self.__sigmoid(dot(activation_values3, self.synaptic_weights3))
return output
if __name__ == "__main__":
neural_network = NeuralNetwork()
print("Random starting synaptic weights (layer 1): ")
print(neural_network.synaptic_weights1)
print("\nRandom starting synaptic weights (layer 2): ")
print(neural_network.synaptic_weights2)
print("\nRandom starting synaptic weights (layer 3): ")
print(neural_network.synaptic_weights3)
# 训练集不变
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
neural_network.train(training_set_inputs, training_set_outputs, 10000)
print("\nNew synaptic weights (layer 1) after training: ")
print(neural_network.synaptic_weights1)
print("\nNew synaptic weights (layer 2) after training: ")
print(neural_network.synaptic_weights2)
print("\nNew synaptic weights (layer 3) after training: ")
print(neural_network.synaptic_weights3)
# 新样本测试
print("Considering new situation [1, 0, 0] -> ?: ")
print(neural_network.think(array([1, 0, 0])))
Ludo’s winning code:
上一周好像就是这个人,这一周又是冠军…教科书般的代码。这里模型和代码的跨度其实比较大了,加入了反向传播的过程,结构可以自定义,用上了循环与迭代。这就一个很完整的多层前馈神经网络模型的实现了。
- 优化方法 : 梯度下降法
- Layers : n fully-connected layers
- 损失函数 : 平方和误差
import numpy as np
np.seterr(over='ignore')
class NeuralNetwork():
def __init__(self):
np.random.seed(1) # Seed the random number generator
self.weights = {} # Create dict to hold weights
self.num_layers = 1 # Set initial number of layer to one (input layer)
self.adjustments = {} # Create dict to hold adjustements
# Python里对于以后要作为数组来使用的变量,要先定义初值。
# 直接将曾加层数的过程定义为了函数,后面可以自由定义神经网络结构
def add_layer(self, shape):
# Create weights with shape specified + biases
self.weights[self.num_layers] = np.vstack((2 * np.random.random(shape) - 1, 2 * np.random.random((1, shape[1])) - 1))
# Initialize the adjustements for these weights to zero
self.adjustments[self.num_layers] = np.zeros(shape)
self.num_layers += 1
def __sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def __sigmoid_derivative(self, x):
return x * (1 - x)
def predict(self, data):
# Pass data through pretrained network
for layer in range(1, self.num_layers+1):
data = np.dot(data, self.weights[layer-1][:, :-1]) + self.weights[layer-1][:, -1] # + self.biases[layer]
data = self.__sigmoid(data)
return data
def __forward_propagate(self, data):
# Progapagate through network and hold values for use in back-propagation
activation_values = {}
activation_values[1] = data
for layer in range(2, self.num_layers+1):
data = np.dot(data.T, self.weights[layer-1][:-1, :]) + self.weights[layer-1][-1, :].T # + self.biases[layer]
data = self.__sigmoid(data).T
activation_values[layer] = data
return activation_values
def simple_error(self, outputs, targets):
return targets - outputs
def sum_squared_error(self, outputs, targets):
return 0.5 * np.mean(np.sum(np.power(outputs - targets, 2), axis=1))
def __back_propagate(self, output, target):
deltas = {}
# Delta of output Layer
deltas[self.num_layers] = output[self.num_layers] - target
# Delta of hidden Layers
for layer in reversed(range(2, self.num_layers)): # All layers except input/output
a_val = output[layer]
weights = self.weights[layer][:-1, :]
prev_deltas = deltas[layer+1]
deltas[layer] = np.multiply(np.dot(weights, prev_deltas), self.__sigmoid_derivative(a_val))
# Caclculate total adjustements based on deltas
for layer in range(1, self.num_layers):
self.adjustments[layer] += np.dot(deltas[layer+1], output[layer].T).T
def __gradient_descente(self, batch_size, learning_rate):
# Calculate partial derivative and take a step in that direction
for layer in range(1, self.num_layers):
partial_d = (1/batch_size) * self.adjustments[layer]
self.weights[layer][:-1, :] += learning_rate * -partial_d
self.weights[layer][-1, :] += learning_rate*1e-3 * -partial_d[-1, :]
def train(self, inputs, targets, num_epochs, learning_rate=1, stop_accuracy=1e-5):
error = []
for iteration in range(num_epochs):
for i in range(len(inputs)):
x = inputs[i]
y = targets[i]
# Pass the training set through our neural network
output = self.__forward_propagate(x)
# Calculate the error
loss = self.sum_squared_error(output[self.num_layers], y)
error.append(loss)
# Calculate Adjustements
self.__back_propagate(output, y)
self.__gradient_descente(i, learning_rate)
# Check if accuarcy criterion is satisfied
if np.mean(error[-(i+1):]) < stop_accuracy and iteration > 0:
break
return(np.asarray(error), iteration+1)
if __name__ == "__main__":
# ----------- XOR Function -----------------
# 这里用亦或方程的输入输出作为样本
# Create instance of a neural network
nn = NeuralNetwork()
# Add Layers (Input layer is created by default)
# 第一层输入层默认创建好了
# 第二层定义为9个神经元,因为第一层有两个神经元,链接(权重)矩阵为2×8
# 第二层定义为1个神经元
nn.add_layer((2, 9))
nn.add_layer((9, 1))
# XOR function
training_data = np.asarray([[0, 0], [0, 1], [1, 0], [1, 1]]).reshape(4, 2, 1)
training_labels = np.asarray([[0], [1], [1], [0]])
error, iteration = nn.train(training_data, training_labels, 5000)
print('Error = ', np.mean(error[-4:]))
print('Epoches needed to train = ', iteration)
# nn.predict(testing_data)
详细代码见:https://github.com/ludobouan/pure-numpy-feedfowardNN
小结
累坏啦,下面的冠军代码看了有三个小时才完整弄明白,好在已经听过吴恩达的神经网络基础了,整个过程还不是很熟悉,现在终于基本理清楚了,不过如果什么都不看的话,估计现在还是很难把整个多层前馈神经网络模型独立编出来,慢慢来吧。